
The robotics industry, bless its circuits, harbours a bit of a grubby secret: coaxing a robot into doing anything remotely useful is an exercise in glacial patience and eye-watering expense. For eons, or so it feels, the received wisdom has been to brute-force intelligence with Vision-Language-Action (VLA) models. These digital beasts demand tens of thousands of human-hours, with poor souls meticulously puppeteering robots through every conceivable, mundane task. It’s less a bottleneck, more a data chokepoint of truly epic, soul-crushing proportions.
Now, robotics firm 1X has sauntered in, casually tossing a solution onto the table that borders on outright heresy. Their fresh take for the NEO humanoid is deceptively straightforward, almost cheeky: ditch the painstaking, hand-holding lessons. Instead, let the robot swot up by simply observing that vast, chaotic, and endlessly instructive library of human shenanigans we affectionately call the internet. This isn’t just a firmware update; it’s a seismic, foundational reshuffle in how a robot can actually get its head around acquiring skills.
The Data-Hungry Beast of Yesterday
To truly grasp the audacious leap 1X is attempting, one must first cast an eye over the rather dusty status quo. Most contemporary foundation models for robotics, from Figure’s Helix to Nvidia’s GR00T, are VLAs. Powerful, yes, but also insatiably peckish for pristine, robot-specific demonstration data. This translates to shelling out serious quid for humans to tele-operate robots for thousands of hours, meticulously gathering examples of, say, picking up a teacup or, heaven forbid, folding a tea towel.
This whole rigmarole is a colossal impediment to birthing truly general-purpose robots. It’s not just pricy; it simply doesn’t scale for love nor money, and the resulting models can be as brittle as a ginger nut biscuit, often packing up their digital bags when confronted with an object or environment they’ve not encountered. It’s akin to teaching a nipper to rustle up a Sunday roast by only letting them observe you in your own galley, rather than letting them binge every single cooking programme ever aired.
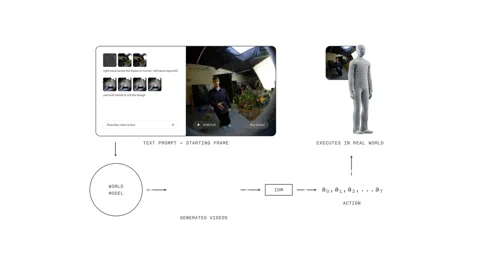
Dream a Little Dream of… Doing Chores
The 1X World Model (1XWM), bless its innovative cotton socks, simply chucks that dusty old playbook straight out the window. Instead of directly mapping language to a series of robotic gyrations, it employs text-conditioned video generation to suss out what needs doing. Think of it as a rather clever two-part brain, effectively granting the robot the uncanny ability to imagine its future before it so much as twitches a digit.
First up, we have the World Model (WM), a 14-billion-parameter generative video model that serves as the system’s very own imagination department. You feed NEO a simple text prompt—say, “pop this satsuma into the lunchbox”—and the WM, surveying the current scene with its digital eye, conjures up a short, utterly plausible video of the task being executed with aplomb.
Then comes the Inverse Dynamics Model (IDM), the no-nonsense pragmatist of the whole contraption, which meticulously analyses that digital daydream. It translates those generated pixels into a concrete sequence of motor commands, deftly bridging the chasm between a visual what and a physical how. This whole shebang is underpinned by a rather clever multi-stage training strategy: the model kicks off with web-scale video, gets its mid-training on 900 hours of egocentric human video for a proper first-person gander, and is finally fine-tuned on a mere 70 hours of NEO-specific data to truly get to grips with its own chassis.

A rather cunning bit of wizardry in their training pipeline is dubbed “caption upsampling.” Given that many video datasets come with descriptions as terse as a taciturn librarian, 1X employs a VLM to whip up richer, more granular captions. This, in turn, provides clearer conditioning and sharpens the model’s knack for following intricate instructions – a technique that’s already proven its mettle in image models like OpenAI’s DALL-E 3.
The Humanoid Advantage
This entire video-first modus operandi pivots on a rather critical, and perhaps blindingly obvious, bit of kit: the robot is, wait for it, shaped like a person. The 1XWM, having gorged itself on countless hours of humans fumbling and flailing through the world, has developed a deep, implicit comprehension of physical priors—think gravity, momentum, friction, object affordances—that transfer directly. Why? Because NEO’s chassis moves in a fundamentally human-like fashion. It’s almost as if they planned it.
As 1X rather eloquently puts it, the hardware isn’t just an afterthought; it’s a “first-class citizen in the AI stack.” The kinematic and dynamic similarities between NEO and us mere mortals mean the model’s learned priors largely hold water. What the model can visualise, NEO can, more often than not, actually pull off. This rather snug integration of hardware and software effectively slams shut that often-treacherous chasm between simulation and the gritty reality of the shop floor.
From Theory to Reality (With Some Stumbles)
The results, frankly, are rather compelling. 1XWM enables NEO to generalise to tasks and objects for which it possesses precisely zero direct training data. The promotional video, which is quite the spectacle, showcases it steaming a shirt, watering a rather parched houseplant, and even, somewhat impressively, operating a toilet seat – a feat for which it had no prior examples. This strongly implies that the nouse for two-handed coordination and intricate object interaction is being rather successfully ported from the human video data.
But hold your horses, this isn’t pure sorcery. The system, like all brilliant things, comes with its own quirks and limitations. Generated rollouts can be “overly optimistic” about success – a bit like a football fan predicting their team will win the league every year. And its monocular pretraining can lead to rather weak 3D grounding, often causing the actual robot to undershoot or overshoot a target, even when the generated video looks absolutely spiffing. Success rates on genuinely dexterous tasks, such as pouring cereal or sketching a passable smiley face, remain, shall we say, a bit of a sticky wicket.
However, 1X has, rather astutely, unearthed a promising avenue to give performance a bit of a shot in the arm: test-time compute. For a deceptively simple “pull tissue” task, the success rate shot up from a rather modest 30% with a single video generation to a more respectable 45% when the system was permitted to conjure up eight different possible futures and cherry-pick the most favourable. While this selection is presently a manual affair, it clearly signposts a future where a VLM evaluator could automate the entire shebang, thereby significantly upping the reliability stakes.
The Self-Teaching Flywheel
The 1XWM represents far more than just a bog-standard incremental update; it’s a potential paradigm shift that could, quite literally, blow the data bottleneck wide open. It effectively sets in motion a virtuous flywheel for self-improvement. By being able to have a crack at a broad spectrum of tasks with a non-zero success rate, NEO can now generate its very own data. Every single action, be it a resounding triumph or a spectacular cock-up, morphs into a fresh training example, ready to be fed back into the model to fine-tune its policy. The robot, you see, is beginning to teach itself. Spiffing.
Of course, it’s not all sunshine and rainbows; some rather chunky hurdles remain stubbornly in place. The WM, bless its digital heart, currently takes a leisurely 11 seconds to conjure up a mere 5-second plan, with the IDM needing another second to extract the actions. That sort of latency, frankly, is an absolute eternity in a dynamic, real-world environment – a complete non-starter for reactive tasks or anything involving delicate, contact-rich manipulation. No chance of it catching a dropping teacup, then.
Still, by tackling the data conundrum head-on with a bit of British grit, 1X may have just well and truly kicked open the door to a future where robots learn not from our interminable, tedious instruction, but from the glorious, chaotic tapestry of our collective, recorded human experience. That future, my friends, is accelerating at a fair old clip, one internet video at a time. Jolly good show.
