
Just when you thought your smartphone’s camera was only good for mediocre concert snaps and food photos, researchers have gone and turned it into a high-octane, real-time 3D scanner. Robbyant, the embodied AI arm of Ant Group, has just released LingBot-Map, a groundbreaking open-source 3D foundation model capable of reconstructing detailed, large-scale environments from a single video stream. The real kicker? It clocks in at a breezy 20 frames per second—a speed that makes traditional photogrammetry methods look like they’re moving at a glacial pace.
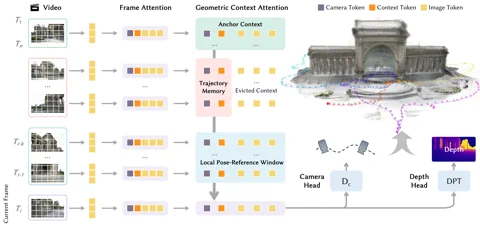
The “secret sauce” behind this performance is a bespoke architecture dubbed the Geometric Context Transformer (GCT). This isn’t just a standard transformer slapped onto a vision task; the GCT was engineered specifically to kill off “drift,” the long-standing bane of monocular (single-camera) SLAM systems. It manages spatial data through three parallel attention mechanisms: an anchor context for rock-solid coordinate grounding, a local pose-reference window for capturing fine-grained detail, and a trajectory memory to iron out errors over massive distances. This allows LingBot-Map to crunch through sequences exceeding 10,000 frames with what Robbyant describes as “almost unchanged accuracy.” The project is live on GitHub right now. Hyperlink: Robbyant/lingbot-map
The performance figures are, quite frankly, audacious. On the notoriously difficult Oxford Spires dataset, LingBot-Map clocked an Absolute Trajectory Error of just 6.42 metres—a nearly 2.8x improvement over the previous gold standard for streaming methods. It even manages to outclass established offline methods that have the luxury of post-processing every frame at once. Meanwhile, on the ETH3D benchmark, it posted a staggering F1 score of 98.98, leaving the runner-up in the dust by over 21 percentage points. For those who want to dive into the technical nitty-gritty, the full methodology is detailed in a new paper on arXiv. Hyperlink: Read the paper on arXiv
Why should we care?
LingBot-Map is a massive leap towards democratising spatial intelligence. By ditching the requirement for eye-wateringly expensive LiDAR sensors or clunky multi-camera rigs, it paves the way for low-cost, high-performance 3D perception in everything from consumer robotics to autonomous vehicles and AR headsets. This isn’t just about generating pretty point clouds; it’s about giving machines a fluid, real-time grasp of the physical world. As a “3D foundation model,” it’s a vital piece of the puzzle in building AI that doesn’t just process pixels or text, but actually perceives, navigates, and interacts with our messy, unstructured reality—the very definition of the future of embodied AI.
