
Google DeepMind has just pulled the curtains back on Gemini Robotics-ER 1.6, the latest iteration of its “Embodied Reasoning” model. The goal? To finally give robots a much-needed dose of common sense when navigating the physical world. This isn’t just a minor tweak; it’s a significant leap in how robots perceive, understand, and interact with their environments, moving us away from machines that follow rigid scripts toward AI that can actually suss out a situation.
The headline feature of Gemini Robotics-ER 1.6 is its vastly improved spatial awareness, perfectly showcased by its new “pointing” capability. Imagine asking a robot to find a specific spanner in a cluttered workshop; the model can now accurately identify, count, and pinpoint the correct tool while ignoring the rest of the kit lying around. This isn’t just about playing “I Spy”—it’s the groundwork for complex spatial logic, like calculating the perfect trajectory for a grip or understanding nuanced commands like “tuck the wrench into the toolbox.” The model can even reason through physical constraints, such as identifying which objects are small enough to fit into a specific container.
The update also tackles one of the most persistent headaches in robotics: knowing when a job is actually “done.” Thanks to advanced multi-view reasoning, Gemini Robotics-ER 1.6 can stitch together live video feeds from multiple angles—say, an overhead bird’s-eye view and a camera mounted on its own wrist—to build a comprehensive 3D understanding of the scene. This prevents the robot from getting stuck in a loop or failing a task just because an object is momentarily hidden from one perspective.
Why this is a game-changer
This update is more than just a spec bump; it’s about laying the foundations for true autonomy. The ability to read analog gauges, fuse multiple camera streams, and grasp complex spatial relationships is exactly what separates a stationary factory arm from a truly useful field robot. According to DeepMind’s official announcement, this is also their safest robotics model to date.
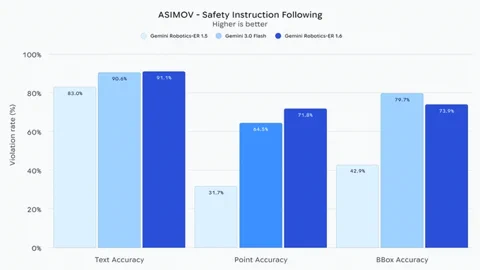
Crucially, Gemini Robotics-ER 1.6 shows a “substantially improved capacity” for sticking to safety protocols. It understands instructions like “steer clear of liquids” or “don’t lift anything over 20kg.” When compared to the baseline Gemini 3.0 Flash model, it’s reportedly 10% better at spotting potential risks to humans in video feeds. This focus on safety and real-world reasoning is a vital step toward robots that can work reliably alongside us in unpredictable, everyday environments. The model is already out in the wild for developers via the Gemini API and Google AI Studio.
